 AIの「文脈理解」が進化する──GraphRAGという新潮流
AIの「文脈理解」が進化する──GraphRAGという新潮流
近年、企業における生成AIの活用が急速に広がる中、「RAG(Retrieval-Augmented Generation)」という技術が注目を集めてきました。AIが回答を生成する際に外部の知識データベースを参照させることで、精度と信頼性を高めるアーキテクチャです。そもそも企業に存在するデータの約7割以上は、メール・音声・メモといった非構造化データと言われています。従来のデータベースでは扱いにくかったこれらの情報を検索対象にできるようになったことが、生成AIが企業にとって戦略的な意味を持ち始めた大きな理由のひとつです。そのRAGに、さらなる革新をもたらす技術として「GraphRAG」が台頭してきました。
──ベクトル検索の限界
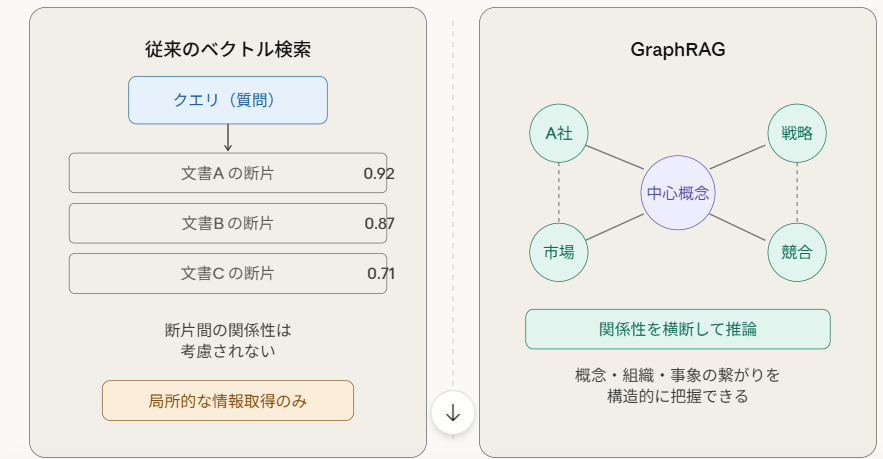
従来のRAGは「ベクトル検索」を基盤としています。テキストをあらかじめ300〜500文字程度のブロックに分割し、それぞれを数値の配列(ベクトル)に変換することで、意味的に近い文書を探し出す手法です。「新製品の価格は?」「昨年の売上推移は?」といった単一の事実を問う質問には高い精度を発揮します。しかし、この分割されたブロック同士は互いに関係を持てないという技術的制約があります。そのため「A社との取引が自社のサプライチェーン全体にどう影響するか」「競合他社の動向と自社戦略の整合性はどこにあるか」といった、複数の情報が複雑に絡み合う問いに対しては、十分な回答を生成することができません。情報の「点」は拾えても、情報間の「繋がり」が見えないという根本的な課題です。
──知識を「地図」として捉えるGraphRAG
GraphRAGはこの課題を根本から解決するアプローチです。情報を個別の断片として保存するのではなく、「A社はB市場に参入している」「B市場ではC社が競合している」といった概念と概念の関係性そのものを、グラフ(網目状のネットワーク)として構造化します。知識全体をネットワークとして保持しているため、一つの問いに対して関連する概念を芋づる式に辿り、俯瞰的な回答を生成することができます。2024年、Microsoft Researchがこの技術の体系的な論文を発表し、業界の注目を集めました。背景には、大規模言語モデル(LLM)の能力向上と、企業が長年蓄積してきた膨大な社内ドキュメントをいかに有効活用するかという経営課題があります。
──従来手法との比較
両者の違いを端的に整理すると、ベクトル検索が「単一事実の高速検索」に優れるのに対し、GraphRAGは「複数概念をまたいだ推論」に強みを持ちます。「○○の定義は何か」「昨年の売上数値は」といった問いにはベクトル検索で十分ですが、「A社との提携が自社のサプライチェーンと競合環境に与える複合的な影響は」といった経営判断の問いには、GraphRAGのアプローチが本質的な優位性を発揮します。一方で課題もあります。社内ドキュメントからグラフ構造を構築する初期コストと、その維持管理の仕組みが必要となるため、ベクトル検索と比較して導入の複雑さは増します。「何を解きたいか」という経営課題を先に明確にすることが、技術選択の前提として重要です。
──経営への示唆
GraphRAGが特に力を発揮するのは、社内に散在する契約書・会議録・報告書などから、経営判断に必要な関係性を即座に引き出す場面です。単なる情報検索を超え、AIが組織の「知識の地図」を持つことで、意思決定の質とスピードが変わります。まだ技術的な成熟過程にあるものの、「情報がある」から「情報の関係性がわかる」への転換は、次世代のAI活用における重要な分岐点となりそうです。
by 亀田 治伸
記事をシェア: